The Project
As I was searching for a final project idea for Northwestern’s Symbolic AI class — “Knowledge Representation and Reasoning.” I heard that my friend Cooper Stringer made a trivia game where he challenged himself to make the answer “Cooper” as many times as possible.
Aha! I can make something to automate this process.
The Data
Wikidata has structured information on pretty much any topic you can think of. Like Wikipedia, the information comes from volunteers on the internet. Unlike Wikipedia, the information is structured in terms of “subject predicate object” triples.
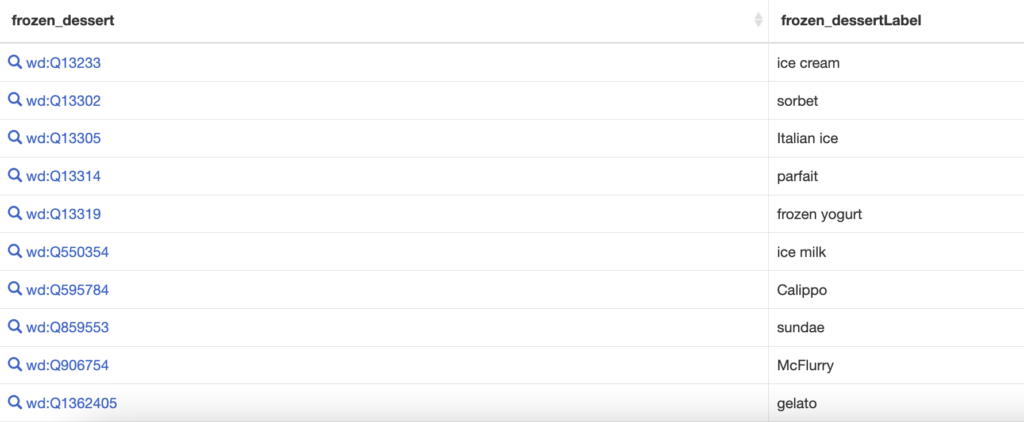
Ice_cream subclass_of frozen_dessert
A query language called “SPARQL”: “SPARQL Protocol and RDF Query Language” is used to search the database by matching a pattern:
?what subclass_of frozen_dessert
matches “Ice cream” but also “sorbet” and others. More complicated queries can match more complicated patterns.
(As a sidenote, RDF is a protocol for triples. Among other things, each term is assigned a unique Q number. Ice cream is wd:Q13233. SPARQL queries use these numbers.)

The Code
The goal is to automate Cooper’s challenge. From a word, make a questions with that as the right answer.
The code can be found under a MIT License at this repository.
We accomplished that in a few steps:
- Get a concept from the user.
- Because many concepts have the same or similar names, we had to “disambiguate” them by offering the user some choices and asking them which they meant. My teammate Anabella Isaro made this part.
- Make a question about the term by finding a fact that is true about that term.
- Find plausible wrong answers.
- Plausible wrong answers share some feature with the right answer, but the fact is not true about them.
- Ask the question.
Issues
Our questions are limited by the information on Wikidata. You can’t really prove a negative given Wikidata, so we relied on “Negation as failure.” That means that if we couldn’t prove something true, then it was considered false. Since Wikidata does not have every fact about everything, this often did not work.
Sometimes a fact is implicit in the database. If Sarah is a professor and a professor is subclass of teacher, then Sarah is a teacher. This kind of thing is where the power of RDF and SPARQL lie. Unfortunately, searching for these kinds of things can be slow. To route around that issue, I made a fast mode and a slow mode. Fast mode does a more exhaustive check that wrong answers are wrong by chaining Subclass_of, instance_of and other rules. When the user selects an answer, the program does the exhaustive check to avoid grading unfairly.
The Host
My project for the Global Poverty Research Lab involves a website backend. The current king of cloud computing is Amazon Web Services (AWS). In particular, AWS Lambda is a powerful and appealing service because the code only runs when someone makes a request, resulting in much smaller costs than if you had a server running 24/7 (for example an EC2 instance).
I decided to put the code for the trivia question generator on Lambda to get practice so that it would be possible to generate trivia questions via GET request.
AWS is not an easy tool to use. The icons for the services are near meaningless, the names for the service are either letters and numbers to memorize (S3, EC2) or nonsensical (the “beanstalk” in “Elastic Beanstalk” refers to the fairy tale Jack and the Beanstalk.) I found it funny that AWS Lambda is not a lambda; it can make requests to other services, changing their state and allowing for inconsistent outputs for the same input.1
I found myself wishing I had a patient mentor who could sit by me and teach me the basics, as I always do when learning a new technology.
Still, I eventually figured it out.
How you can use it
you can now disambiguate a word by visiting:
https://baenccxbra.execute-api.us-east-2.amazonaws.com/dev/disambiguate/example
and get an element_question from a Qid using:
https://baenccxbra.execute-api.us-east-2.amazonaws.com/dev/question/for_answer/Q13233
- My parents didn’t find this funny, even after I explained the joke! ↩︎